Offline Reinforcement Learning
Reinforcement Learning(RL), as simply stated in Sutton and Barto Sutton and Barto (2018) , is learning what to do i.e map situations to actions to maximize the cumulative reward for a series of steps. Naturally, trial and error is at the core of Reinforcement Learning i.e. RL learns in a hands-on approach exploring and exploiting its task, which is referred to as online learning, where online refers to agent manipulating the surroundings around it(commonly referred to as an Environment) with the available controls it has(referred to as actions). While such approaches have been popular and successful in many tasks, they often rely on continually improving the ability to search better and learn on the go, which does not translate well to tasks where the ability to explore the environment comes with a cost, which harms the ability of most state-of-the-art algorithms to learn. Hence, Offline Reinforcement Learning is a paradigm within RL that is tasked to learn optimal behaviour from a static dataset i.e. the available data is fixed and cannot be controlled, as it is often generated from an external agent. The figure below illustrates the key difference between traditional RL and offline RL.
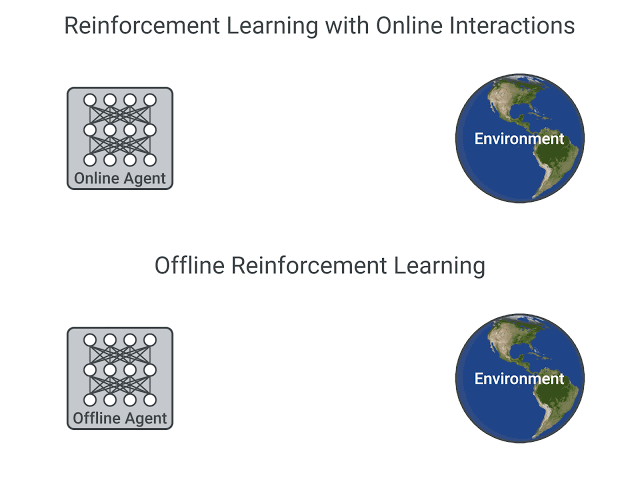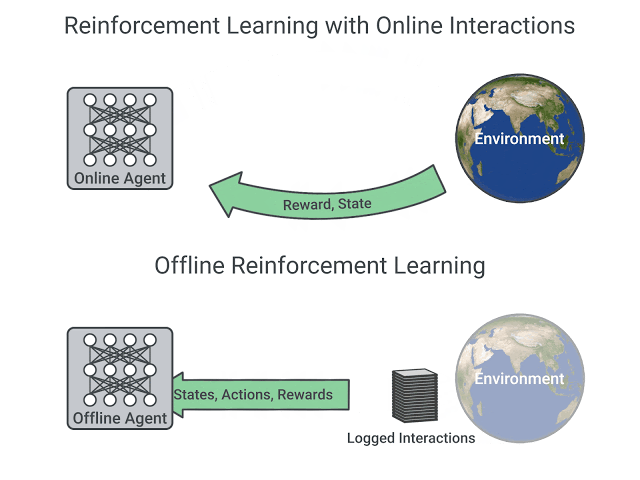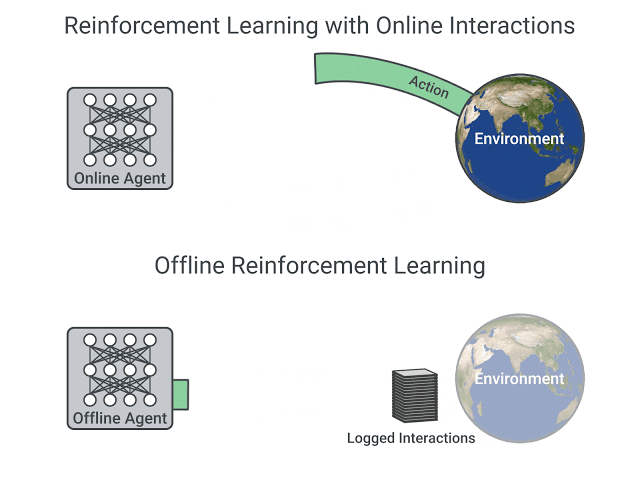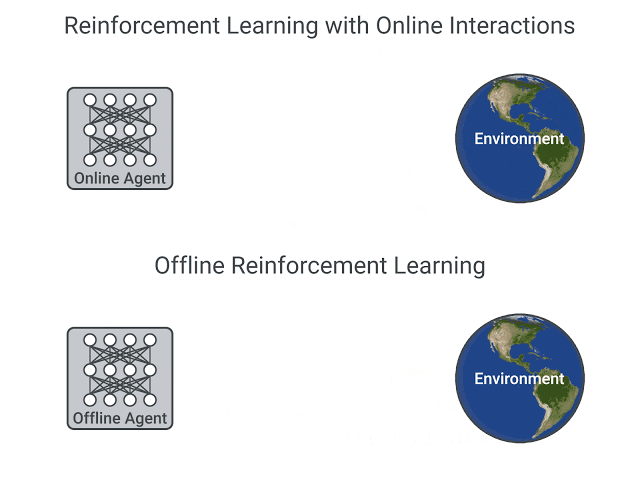
In this post, I cover some popular algorithms and code excerpts that help understand some of the implementation details regarding these algorithms to provide the intuition of how they work. For more documentation on how to run these algorithms, you can check out my repository that implements these algorithms in detail at Offlax:
Conservative Q-Learning Kumar et al. (2020)
Conservative Q-Learning(CQL) builds on top of existing algorithms like QR-DQN(for discrete action spaces) and SAC(for continuous action spaces). As the paper suggests, CQL only requires 20 lines of additional code over the existing RL algorithms like QR-DQN and SAC.
TD3 + Behavior Cloning Fujimoto and Gu (2021)
Behavior cloning is a widely used techniques to for agents to learn from an expert i.e. trying to understand based on an expert agent’s trajectory. This paper suggests using Behavior Cloning with some adjustments over an existing RL algorithm like TD3 to learn in from a static dataset of trajectories.
References
Citation
@online{balloli2023,
author = {Balloli, Vaibhav},
title = {Offline {Reinforcement} {Learning}},
date = {2023-01-28},
url = {https://vballoli.github.io/research-recap//posts/offline-rl},
langid = {en}
}